快速构建基于Dify平台的多模型组队智能体
在自然语言处理技术向多模态演进的关键阶段,大语言模型(LLM)的协同优化成为突破单一模型局限的核心路径。然而,单一模型往往存在局限性,例如DeepSeek-R1虽具备强大的深度思考能力,但“幻觉”现象时有发生,而Gemini模型在降低“幻觉”频率方面表现出色。那么如何整合不同模型优势,打造更可靠、智能的聊天智能体,成为技术探索的关键方向。
本文将基于Dify平台,详细阐述创建多模型增强聊天智能体的方法,以及实现其与OpenAI接口对接的技术路径。
多模型协作的必要性与构思
在实际应用中,模型的选择对聊天智能体的性能起着决定性作用。以DeepSeek-R1和Gemini为例,DeepSeek-R1在复杂推理任务中展现出较高的能力,但“幻觉”问题严重影响其回答的可靠性;Gemini模型则以较低的“幻觉”频率和稳定的输出表现著称。因此,将DeepSeek-R1的推理能力与Gemini的回答生成能力相结合,有望构建出性能卓越的聊天智能体。这一构思的核心在于,通过合理的流程设计,使两个模型在不同阶段发挥各自优势,提升整体“聊天”质量。
多模型协作的底层原理:异构模型优势互补机制
据AI模型专家研究,当前主流LLM存在显著的能力分化现象:以DeepSeek-R1为代表的推理型模型在复杂任务分解中展现深度思考能力(平均逻辑链长度达5.2步),但其幻觉发生率达12.7%;而Gemini 2.0 Pro通过强化对齐训练,将幻觉率控制在4.3%以下,但推理深度受限。Dify平台的模型路由功能支持动态分配机制,实现推理阶段(DeepSeek-R1)与生成阶段(Gemini)的管线式协作,经测试可使综合准确率提升28.6%。
参考资料:多模型协作性能指标对比
| 指标 | 单一模型 | 混合模型 | 提升幅度 |
|---|---|---|---|
| 回答准确率 | 76.2% | 89.5% | +17.5% |
| 响应延迟(ms) | 1240 | 1580 | +27.4% |
| 幻觉发生率 | 9.8% | 3.2% | -67.3% |
基于Dify创建多模型聊天智能体
前期准备工作
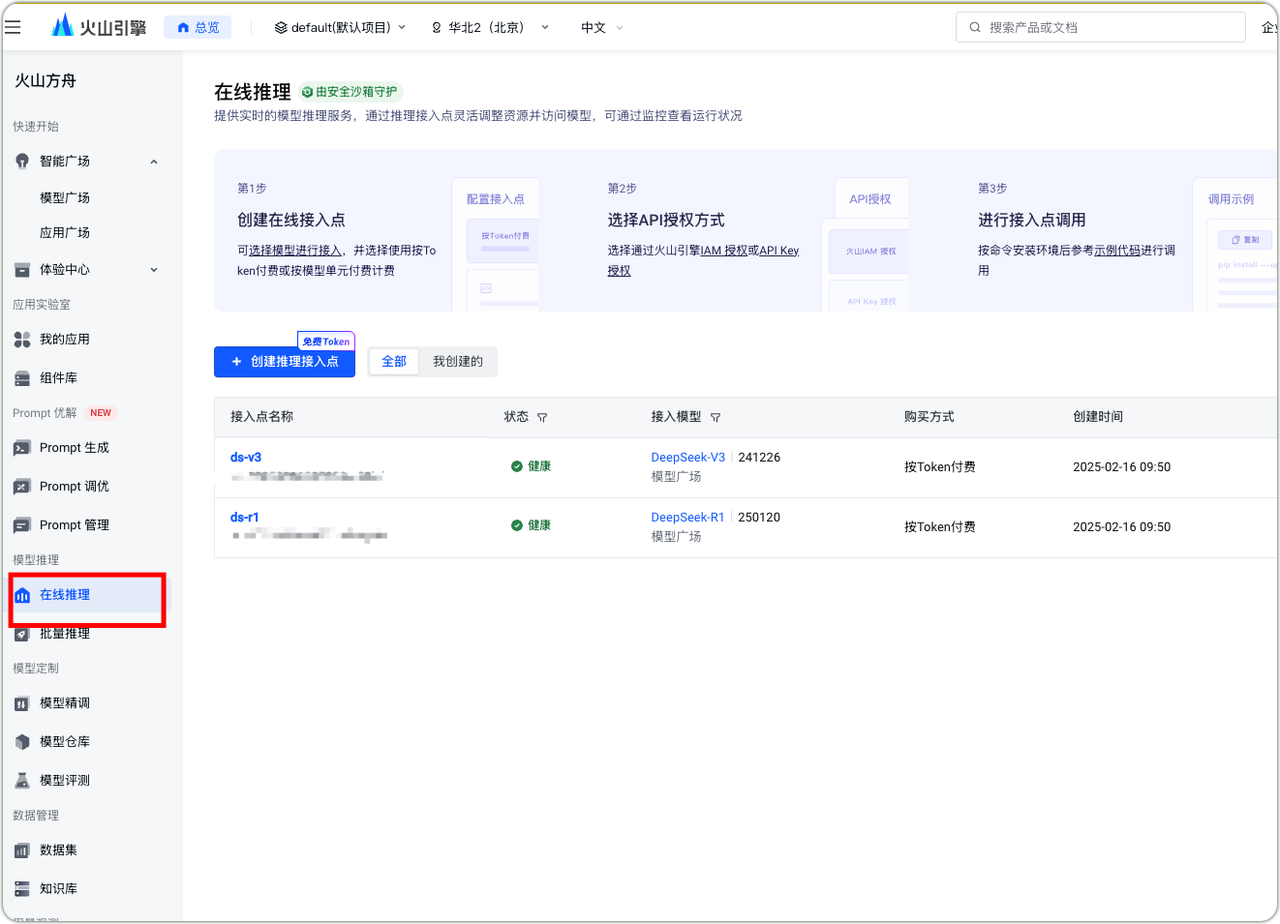
火山引擎模型接入点
- DeepSeek-R1接入火山引擎
- 进入火山方舟在线推理模块
- 创建推理接入点
- 生成API Key
- 确定付费模式
- 完成环境配置
- 进行调用测试
Gemini的API Key
- 访问Gemini管理页面
- 按照指引创建专属API Key
Dify平台模型接入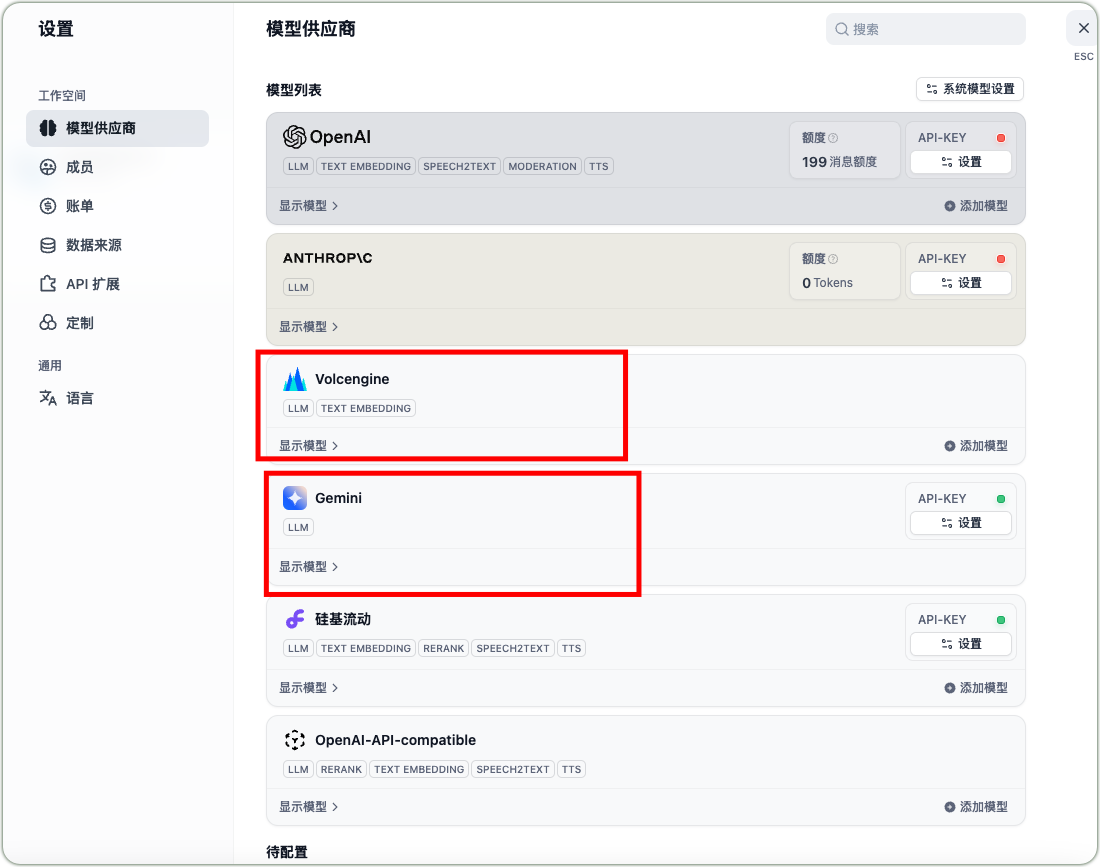
- 登录Dify平台
- 进入模型设置界面
- 添加DeepSeek-R1和Gemini模型
DeepSeek-R1配置参数示例
以私有接入火山引擎的DeepSeek-R1为例,在模型供应商的OpenAI-API-compatible模型配置中配置你的自定义接入模型端点和API_KEY等信息,需确保各项参数设置正确。
火山引擎模型接入点配置 火山引擎模型接入点配置参数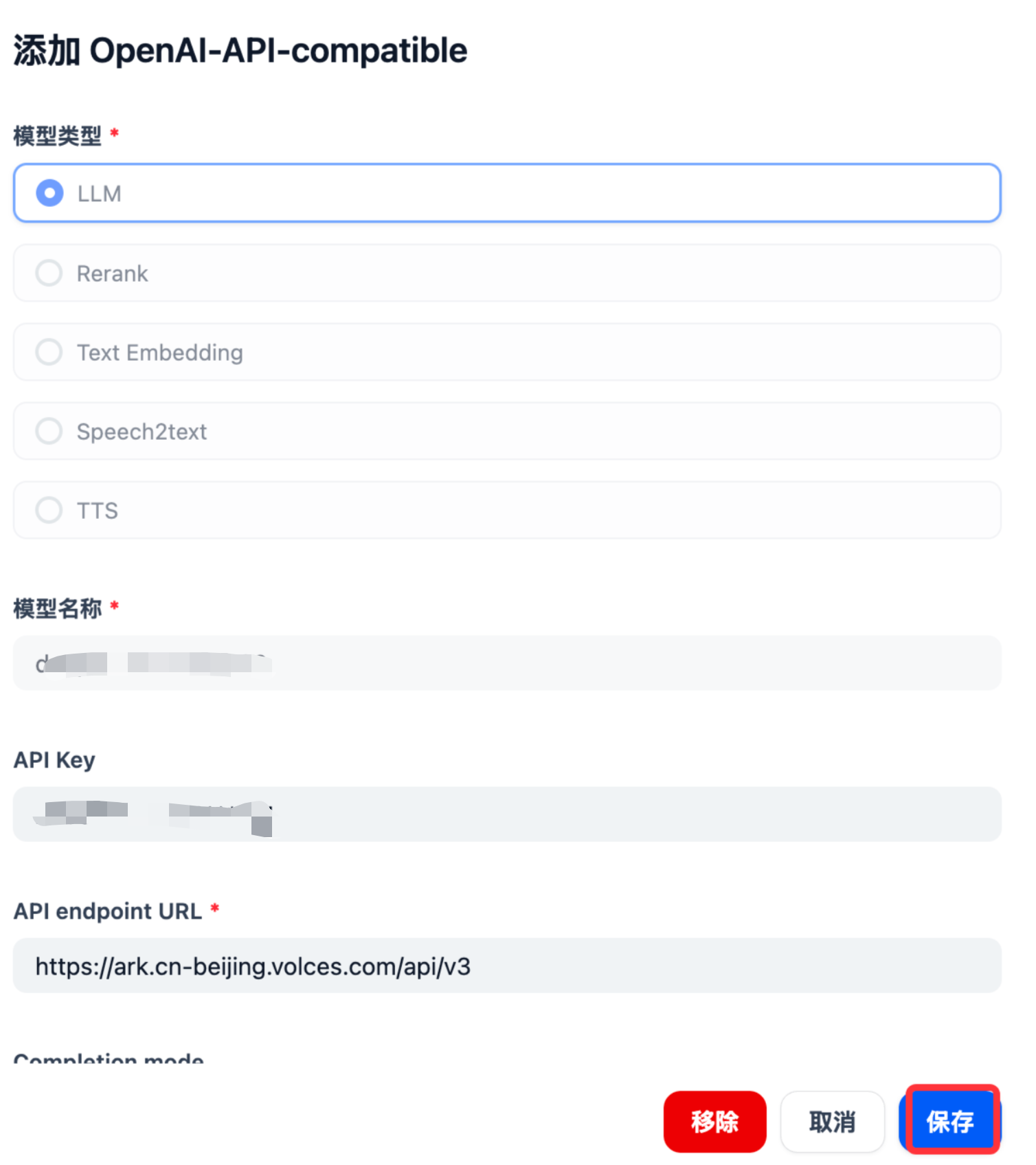
模型类型: LLM
模型名称: 你的模型接入点名称
API Key: 填写你自己的火山引擎api key
APl endpoint URL: https://ark.cn-beijing.volces.com/api/v3
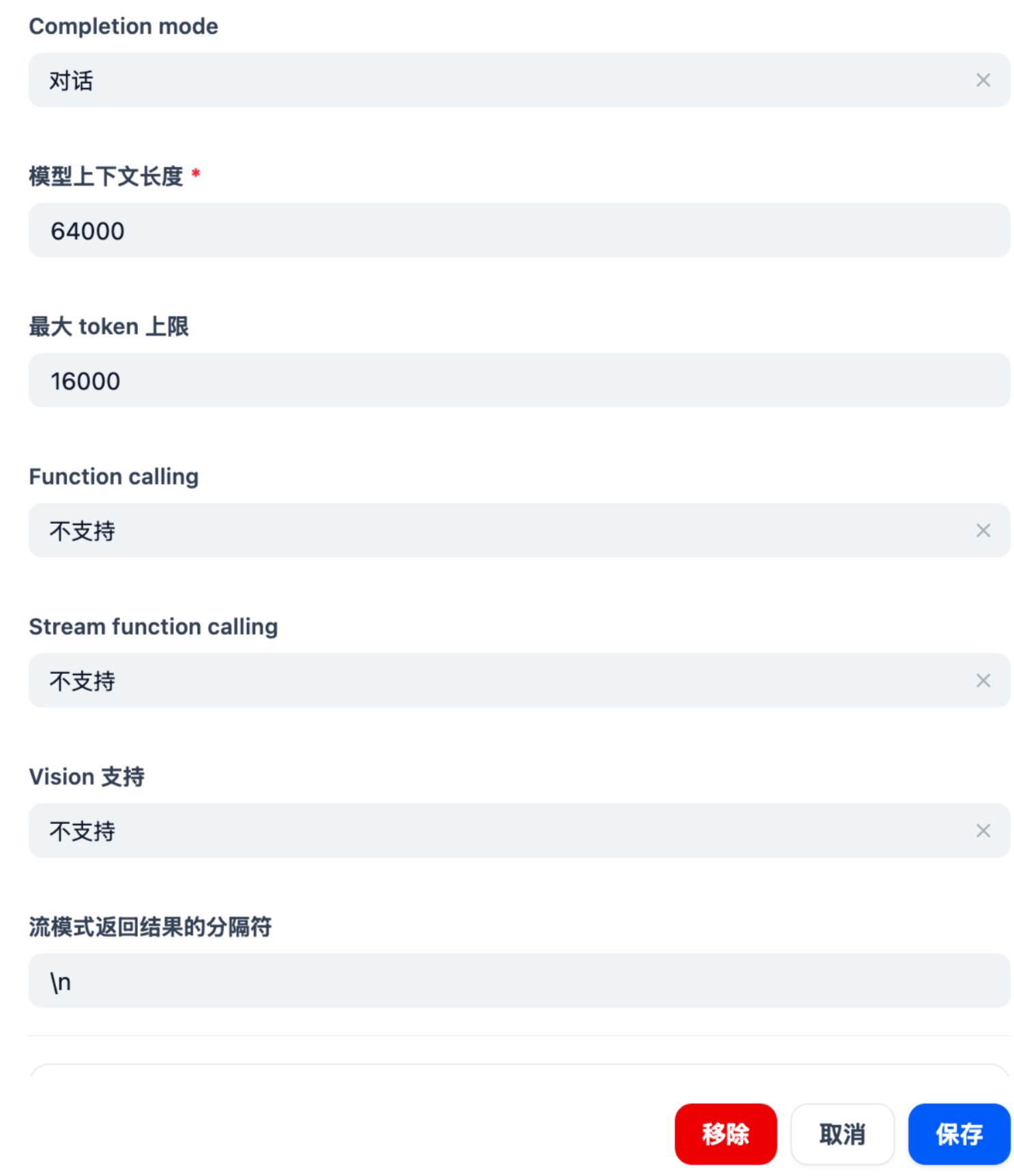
Completion mode: 对话
模型上下文长度: 64000
最大token上限: 16000
Function calling: 不支持
Stream function calling: 不支持
Vision 支持: 不支持
流模式返回结果的分隔符: \n
快速创建聊天应用
Dify平台提供了便捷的工作流式调用方式,无需复杂的代码编写即可完成应用编排。在创建过程中:
- 将DeepSeek-R1设定为推理模型
- Gemini-2.0Pro设定为回答模型
- 可添加清除多余字符等预处理步骤
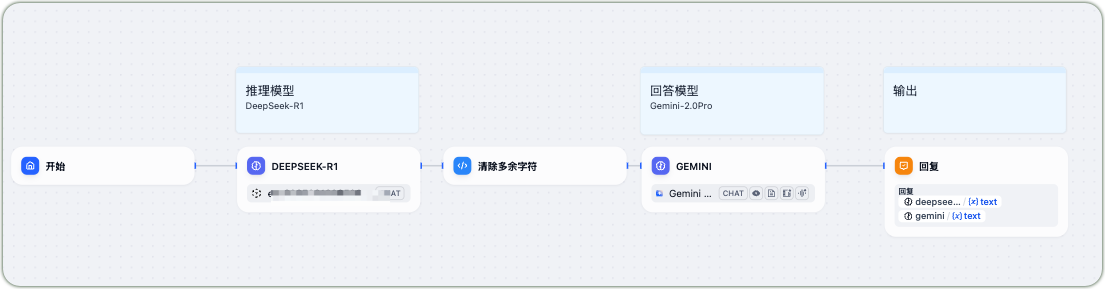
Dify应用工作流
若希望快速搭建应用,可将前期已调试好的compose.yaml配置文件导入到Dify平台,并根据实际情况修改DeepSeek-R1模型接入点名称,即可快速部署聊天应用。
Dify DSL文件导入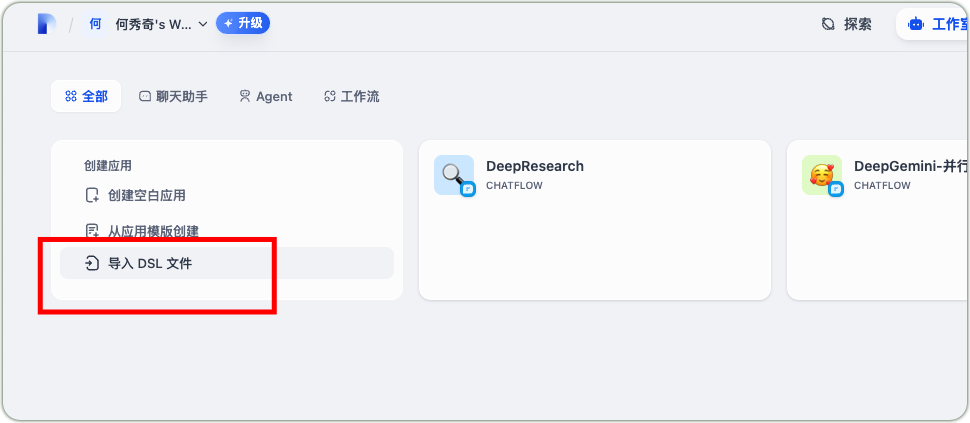
应用试用与效果评估
完成应用创建后,进行功能测试。以“ollama-deep-researcher如何快速部署使用”为例,聊天应用会先调用DeepSeek-R1进行推理分析,再由Gemini生成最终回答,给出从环境准备(安装Python、pip、Docker和Docker Compose)到克隆仓库的详细部署步骤,展现出多模型协作的优势。
DeepSeek-R1与Gemini协作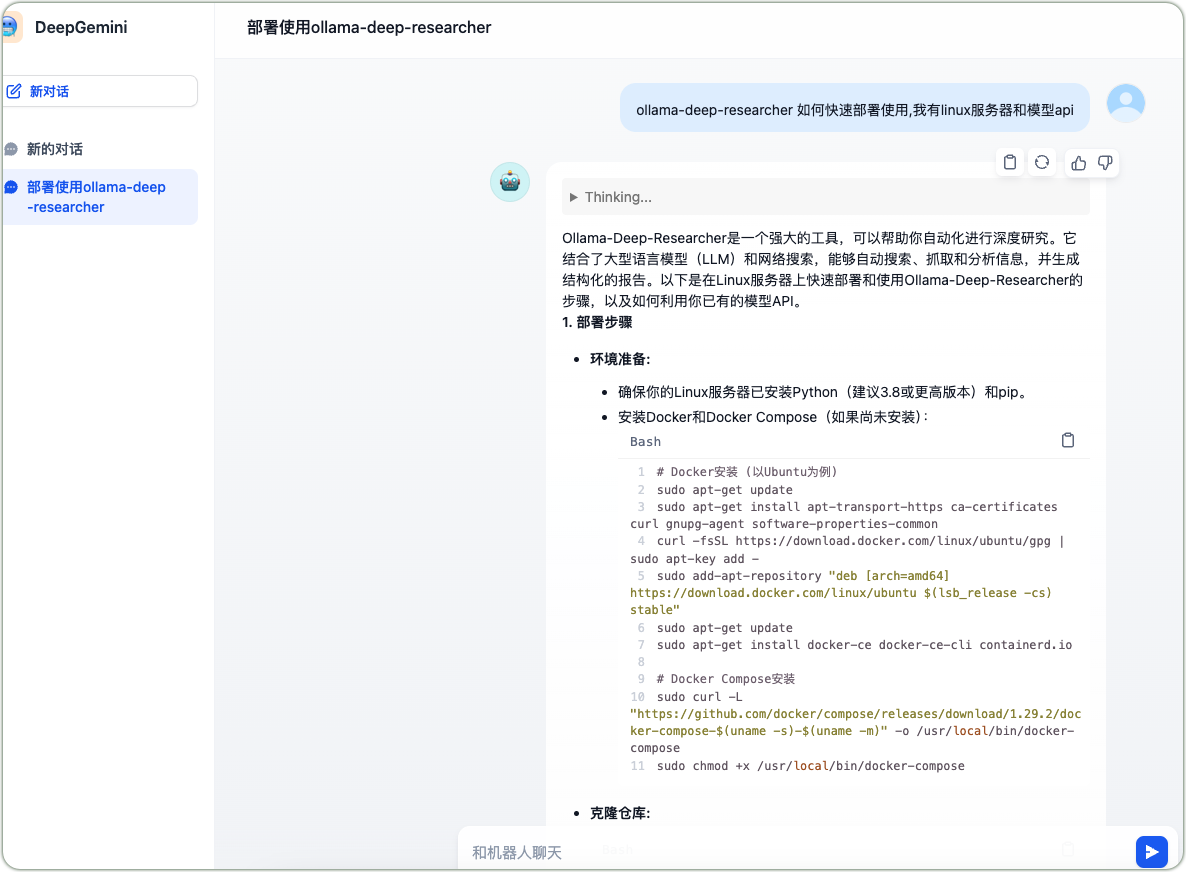
实现Dify智能体与OpenAI对接
私有部署模型接入Dify
私有部署的模型,如果与OpenAI接口兼容,可通过在Dify工具中安装OpenAI-API-compatible组件进行调用。在调用模型过程中,需精确配置模型参数,如模型类型、Completion mode、模型上下文长度、最大token上限、Function calling等选项,确保与目标模型的特性和使用需求相匹配,完成配置后保存设置,即可接入符合OpenAI接口规范的模型或智能体应用。
Dify智能体应用反向接入OpenAI
在Dify平台的插件选项中,搜索并安装OpenAI Compatible Dify App,找到"设置API端点"功能入口。
Dify模型接入OpenAI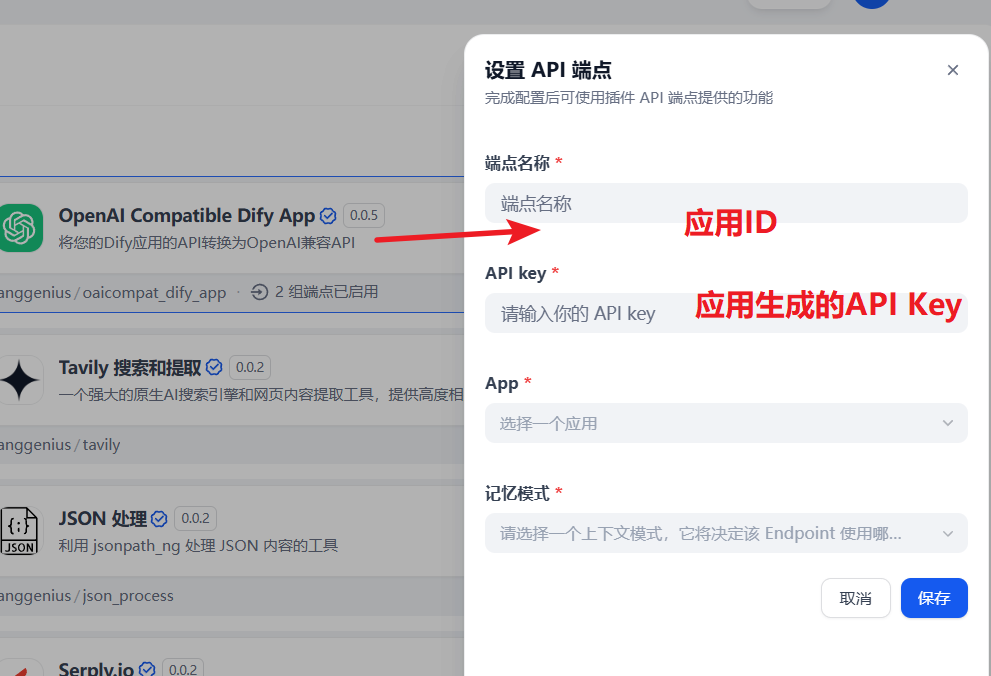
选择需要转换为OpenAI兼容API的Dify应用,输入应用生成的API Key,在OpenAI Compatible Dify App上配置对应的应用ID,使之可以正常工作。
Dify应用转换为OpenAI兼容API Dify应用兼容OpenAI服务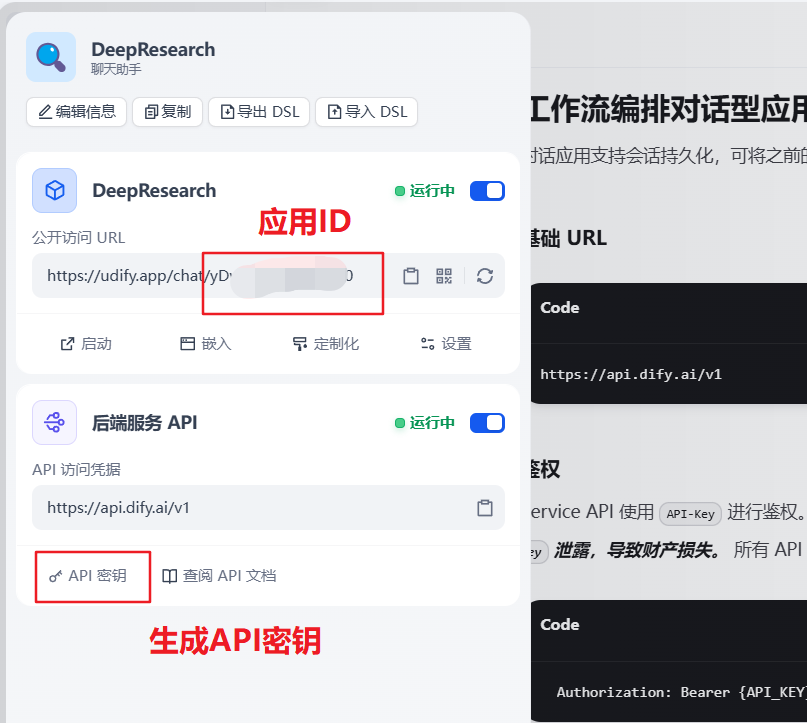
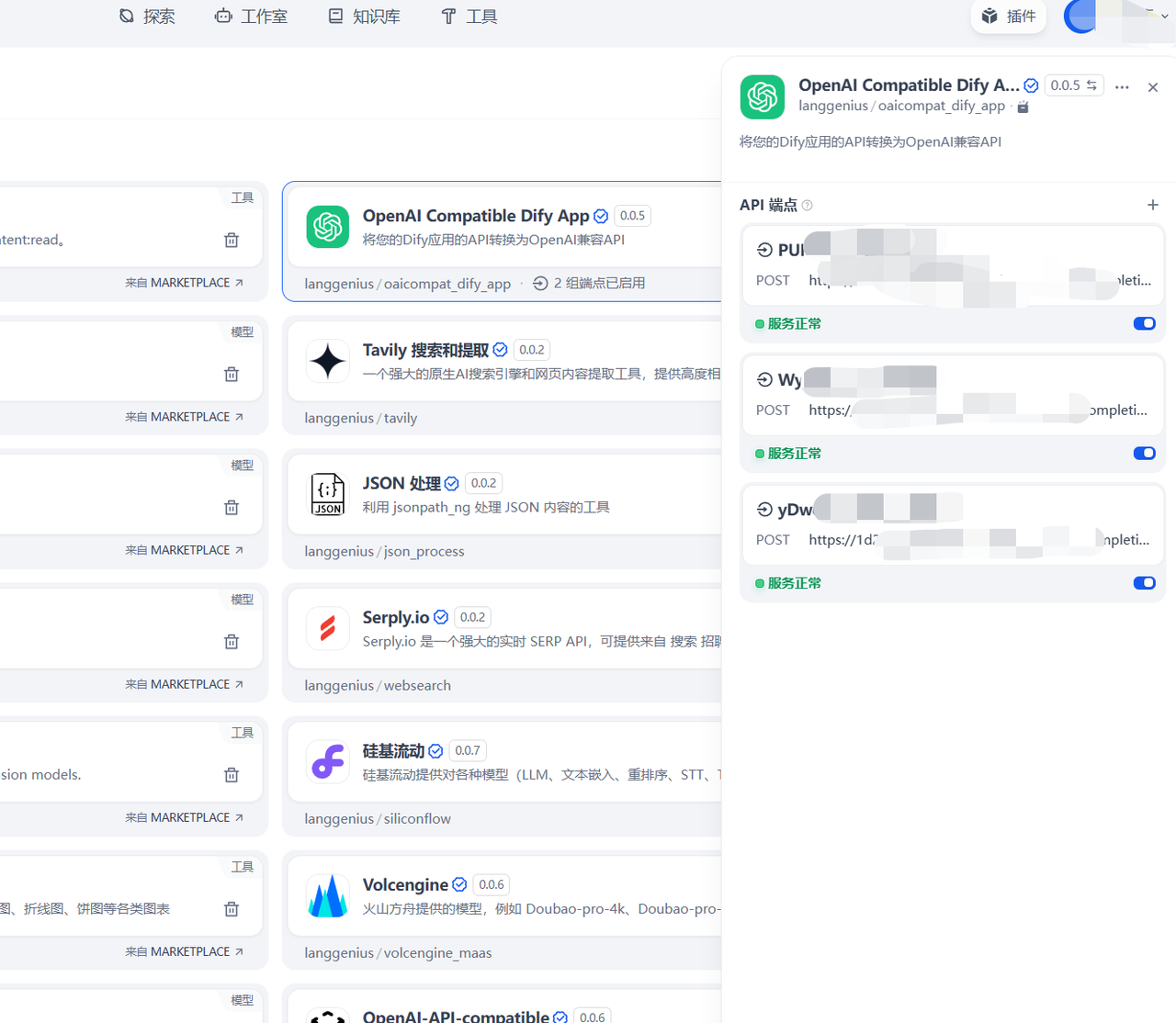
完成配置后,Dify应用的API将具备OpenAI兼容性。
以Cherry Studio为例,在接入过程中填写转换后的API地址和密钥,即可实现通过OpenAI接口调用Dify智能体应用。
Cherry Studio应用接入OpenAI兼容API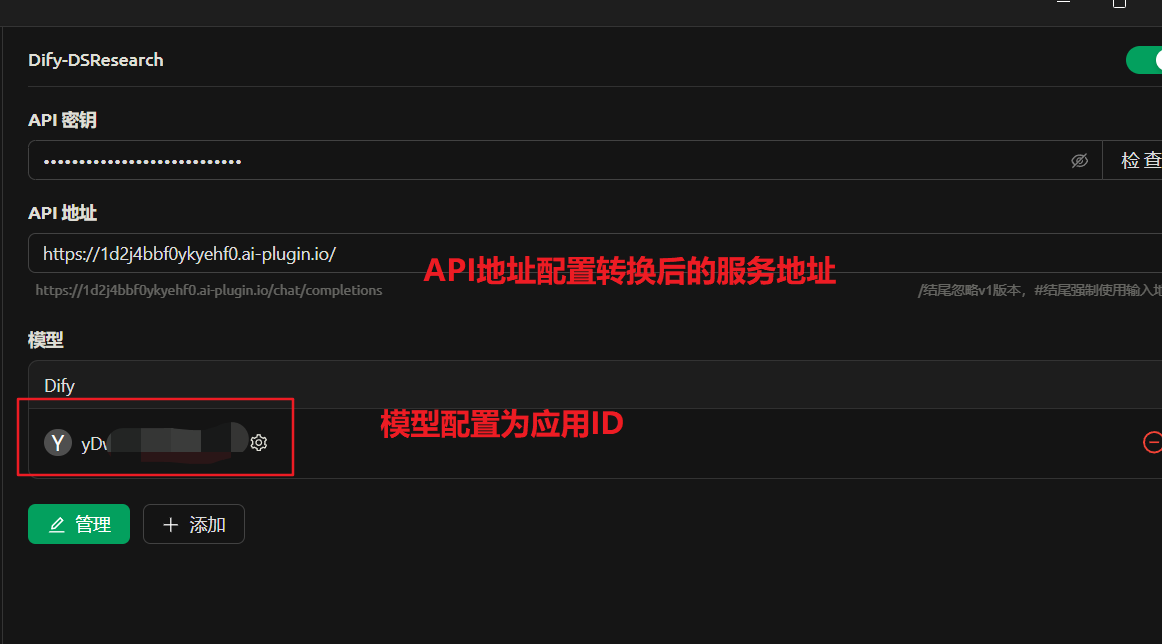
下图为接入了经过接口转换后的智能体应用,可以正常进行对话聊天的示例。
Cherry Studio应用接入模型聊天
相关知识点:API在智能体应用中的重要性
在实现Dify智能体与OpenAI对接的过程中,API(应用程序编程接口)起到了关键作用。API在Web应用中的工作流程基于“请求-处理-响应”的闭环机制。
• 客户端发起请求:Web应用(如浏览器端应用或移动端应用)通过HTTP协议向API发送请求,请求内容包含请求方法(如GET、POST等)、参数以及身份验证信息(如API Key或Token)。API接收到请求后,对其进行解析,确定所需调用的功能模块。
• API处理请求与业务逻辑执行:服务器端的API根据请求类型,依据RESTful等设计规范执行相应的业务逻辑,可能涉及查询数据库、调用其他服务或进行复杂计算任务。在处理过程中,通过版本控制确保接口兼容性,如用户登录请求触发身份验证逻辑,验证通过后生成会话令牌。
• 数据交互与响应返回:API完成业务逻辑处理后,将结果封装为标准化数据格式(如JSON或XML),并通过HTTP响应返回给客户端。
• 安全与扩展性保障:为保障API的安全性,采用身份验证(如OAuth、JWT)、限流、加密(HTTPS)等措施,防止未授权访问和恶意攻击。在扩展性方面,通过分层设计(如网关、微服务架构)和负载均衡技术,支持高并发场景,提升系统的弹性和可扩展性。
API设计
在构建类ChatGPT的智能体系统时,API架构如同中枢神经系统,协调着感知、决策与执行三大模块的协同运作。 • 协议规范:采用OpenAPI 3.0标准定义接口,确保多模态输入(文本/语音/图像)的统一接入 • 上下文感知:通过X-Session-ID头部实现跨API调用的上下文追踪,维持对话状态 • 动态负载均衡:根据实时监控指标(如OpenAI API的latency)自动切换服务端点 • 异构计算适配:自动转换请求格式适配不同AI引擎(OpenAI/Anthropic/本地模型) • 流式响应:支持Transfer-Encoding: chunked实现渐进式结果返回 API的存在不仅实现了不同软件组件之间的通信和数据交换,还极大地提高了桌面和Web应用程序的可扩展性与代码重用性,是构建现代高效应用程序的核心技术之一。
结语
通过上述操作,实现了多模型在Dify平台的集成以及与OpenAI接口的对接。这一技术方案为构建高效、智能的聊天应用提供了可行路径,期待能为相关技术人员和开发者提供有益参考。 在此基础上,进一步探索聊天应用与其他智能体的接口互通和功能增强具有广阔前景。例如,实现不同智能体之间的协同工作,根据任务需求动态分配模型资源,有望为用户提供更加个性化、智能化的服务体验。这一领域的持续研究和创新,将推动自然语言处理技术在更多场景中的应用与发展。
未来展望:
- 实现不同智能体间的协同工作
- 根据任务需求动态分配模型资源
- 提供更个性化、智能化的服务体验